
In this final part to our level 2 mathematical modelling series, we move to a different way of solving our street crossing problem: numerics. We go over discretization of the problem, how to simulate it, and compare with results from part 2.
Quick Recap
In the first part of this series, we outlined a mathematical model describing a person (the walker) crossing a rectangular 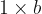
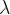
![E[f] = \lambda\displaystyle\int_0^b\sqrt{1+(f'(x))^2}\,e^{-\lambda\int_0^x\sqrt{1+(f'(y))^2}\,dy}\left[\int_0^x\sqrt{1+(f'(z))^2}\,dz + |1-f(x)| + |b-x|\right]\,dx \\ \phantom{\left[\int_0^x\sqrt{1+(f'(z))^2}\,dz + |1-f(x)| + |b-x|\right]}+ e^{-\lambda\int_0^b\sqrt{1+(f'(y))^2}\,dy}\displaystyle\int_0^b\sqrt{1+(f'(x))^2}\,dx.](https://s0.wp.com/latex.php?latex=E%5Bf%5D+%3D+%5Clambda%5Cdisplaystyle%5Cint_0%5Eb%5Csqrt%7B1%2B%28f%27%28x%29%29%5E2%7D%5C%2Ce%5E%7B-%5Clambda%5Cint_0%5Ex%5Csqrt%7B1%2B%28f%27%28y%29%29%5E2%7D%5C%2Cdy%7D%5Cleft%5B%5Cint_0%5Ex%5Csqrt%7B1%2B%28f%27%28z%29%29%5E2%7D%5C%2Cdz+%2B+%7C1-f%28x%29%7C+%2B+%7Cb-x%7C%5Cright%5D%5C%2Cdx+%5C%5C+%5Cphantom%7B%5Cleft%5B%5Cint_0%5Ex%5Csqrt%7B1%2B%28f%27%28z%29%29%5E2%7D%5C%2Cdz+%2B+%7C1-f%28x%29%7C+%2B+%7Cb-x%7C%5Cright%5D%7D%2B+e%5E%7B-%5Clambda%5Cint_0%5Eb%5Csqrt%7B1%2B%28f%27%28y%29%29%5E2%7D%5C%2Cdy%7D%5Cdisplaystyle%5Cint_0%5Eb%5Csqrt%7B1%2B%28f%27%28x%29%29%5E2%7D%5C%2Cdx.+&bg=ffffff&fg=111111&s=2&c=20201002)
In part 2, we discussed some analytic results that one could obtain from this very difficult problem. We showed or argued that there were two transformations that mapped an optimal path on one road to another optimal path on a different road. Then, we used perturbation theory to approximately solve the problem in the case where traffic on the road was light. We will want to compare the results from this part to the perturbative results, so I will quote them here. We expanded the function representing the path to second order in

We then used the equation of motion (which can be found in part 2) to find 


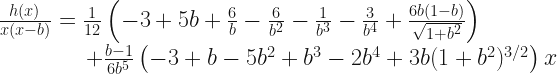
With this information, we can now discuss our final attempt at solving this problem, putting it onto a computer. We will go over the process of how to reformulate the problem so that a computer can actually handle it, and then we will compare these non-perturbative solutions to those we obtained with perturbation theory in the last part.
Discretization – Overview
Our problem is based in calculus: we want to minimize a functional (![E[f]](https://s0.wp.com/latex.php?latex=E%5Bf%5D&bg=ffffff&fg=111111&s=1&c=20201002)

Before we get into the how of discretization, we should discuss the what, that is, what is it that we want to discretize? In part 2, we saw the expected distance functional and the equation of motion. Depending on taste, we could use either one of these to solve the problem. In this post, we will be discretizing the functional. As someone who isn’t too comfortable with more sophisticated computational methods, this is the easier option. The goal is then to calculate the expected distance for some path and then try to deform the path so that we are always decreasing the expected distance.
We want to discretize a functional. How do we do it? The fundamental object in our model is the path. The path is continuous, which is bad for a computer, as we described above. Therefore, we will have to discretize the path in order for the computer to be able to calculate with it. We will see that once the path is discretized, everything else will be calculable on the computer.
Discretization in Action
We want to discretize the path. In other words, we want to chop up the path into a finite number of simple bits so that the computer will be able to handle each one. Let’s take each bit of the path to be a straight line. We will see that this will make computations easier than other possible options.

We will say that there are 


Once we have discretized the path, the rest is easy! Everything else we need in order to calculate
If we want to find the minimum expected distance, then we are going to want to deform the path in such a way that the expected distance decreases. There are different methods of doing this (I personally implemented two different ones), but we are going to focus on gradient descent. We can imagine the space of discretized paths as living in an 

![[0,b]\rightarrow[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2Cb%5D%5Crightarrow%5B0%2C1%5D&bg=ffffff&fg=111111&s=1&c=20201002)

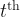

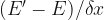

Because we can’t know for sure whether we are at the minimum, we just say that since the gradient disappears at the minimum, we should keep descending until the gradient becomes very small (where we have to decide what “very small” means). That way, when we stop, we should be near a minimum. There are some subtleties here about local vs. global minima, but we will ignore those in this post.
As you might expect, the code runs more quickly with smaller values of 

Results
Let’s dive into the results of the computational scheme outlined above. We will do a brief survey of solutions, stepping through different values of 

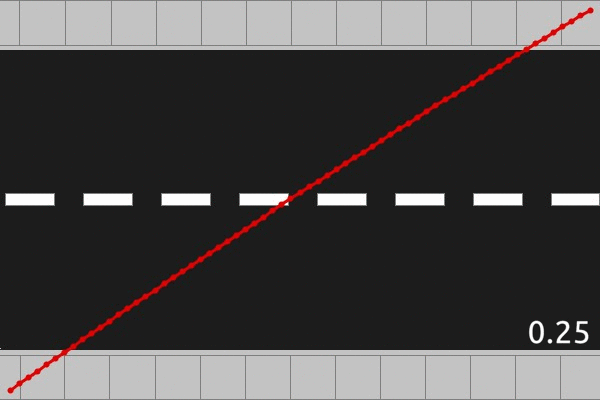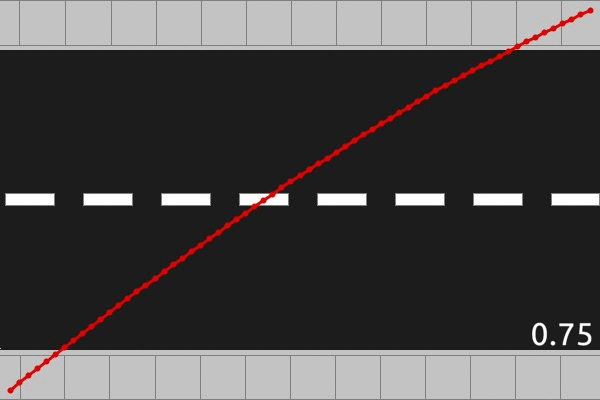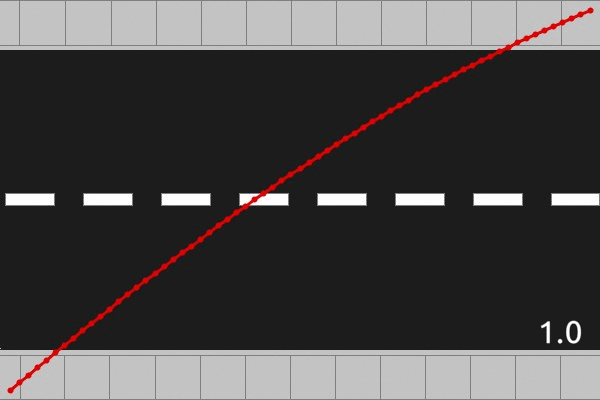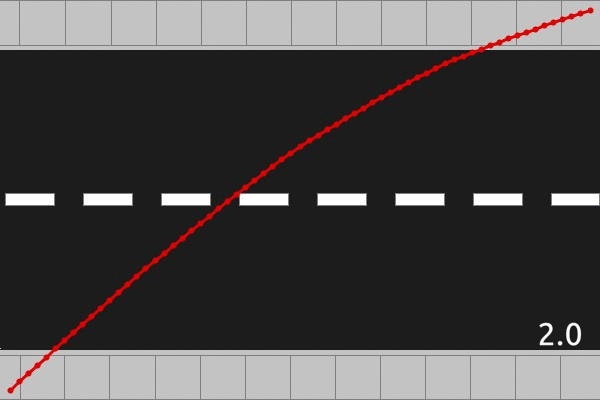

The above animations are displaying the optimal solutions for three different road lengths, 0.5, 1.5, and 2.0, and each frame of the animation represents a different traffic rate. There are some qualitative features that we should make note of, which seem to hold in general. For roads of length less than 1, the optimal path is concave up, whereas for roads of length greater than 1, the optimal path is concave down. This fits with the mirror symmetry property we looked at in part 2. The other major qualitative feature appears when
Mirror Symmetry
In part 2, we made the claim, with a rough idea of a proof, that there is a transformation that maps solutions on a 



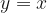

There is one difficulty in producing these sorts of plots, which exposes a downside of using this particular algorithm. When using values of 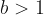

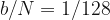
Self-similarity
The self-similarity property was also laid out in part 2, though it was only an argument, without even a suggestion of a proof outline. We will test that claim now. The proposal was that, starting with the optimal path, one could remove some portion of the beginning of the path, then translate and re-scale everything so that we had a new, valid set-up. This would produce another optimal path on a different road with a different traffic rate.
In more detail, say we have an optimal path, 


![(f\left([1-f(s)]x+s\right)-f(s))/(1-f(s))](https://s0.wp.com/latex.php?latex=%28f%5Cleft%28%5B1-f%28s%29%5Dx%2Bs%5Cright%29-f%28s%29%29%2F%281-f%28s%29%29&bg=ffffff&fg=111111&s=1&c=20201002)


To test this, I used the optimal path on a 
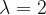


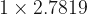

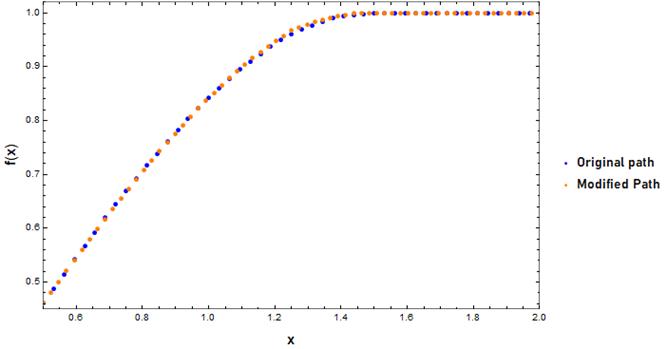
I was very confident when laying out the mirror symmetry property in part 2 because I had done the proof myself. When it came to the self-similarity property, I was less sure, though I felt the argument was very persuasive. When I published part 2, I hadn’t yet checked whether the self-similarity property held using my code. This was a bit nerve-wrecking, but I am pleased that it turned out alright.
Comparing to Perturbation Theory
Let’s compare the results from the code to those that we obtained using perturbation theory in part 2. Let’s quickly recall the perturbative results. The path is expanded in powers of
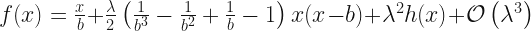
We are going to ignore the 
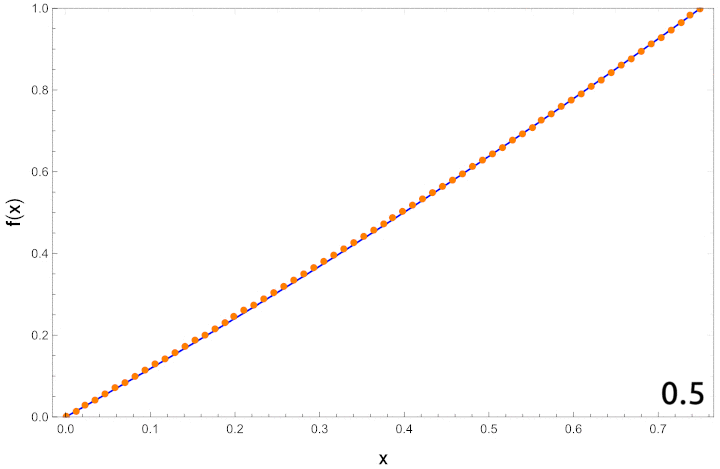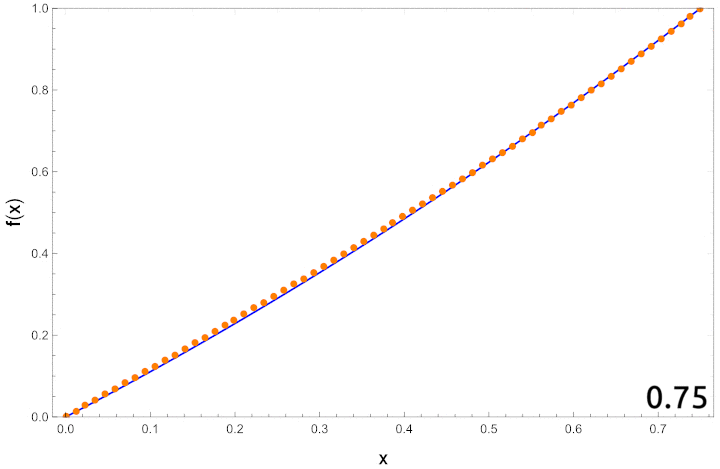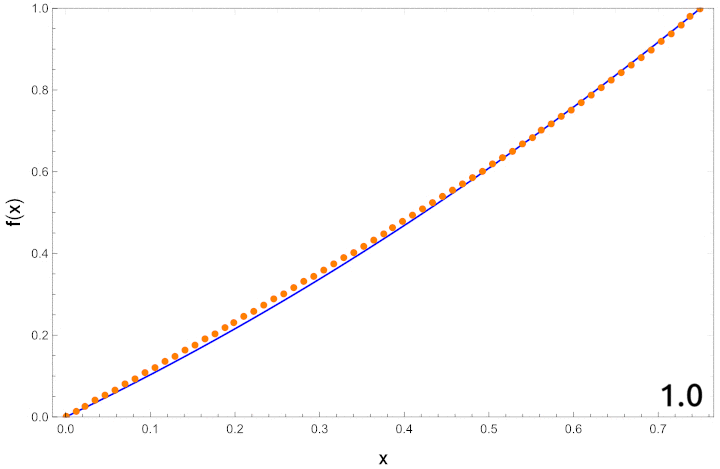

These show how good the approximation is as 
Conclusion
That concludes this series. We looked at a model of a pedestrian crossing a road, with limited prior knowledge of when cars would appear. Then we tried to optimize a path across the road which would take the least amount of time on average. We used symmetry arguments to obtain non-perturbative information about optimal paths, and we used perturbation theory to obtain approximately optimal paths, which were valid for small enough traffic rates. In this post, we placed the optimization problem on a computer by discretizing the path and implementing a gradient descent algorithm to find the smallest expected distance. Then, we used this code to verify the symmetries of the problem and test the robustness of the first order perturbative solution.
Are there any applications of this to the real world? To be honest, I don’t really care about that, I just wanted to answer this question that I’ve been thinking about for a number of years. However, I could see some weird future, where Amazon warehouses are staffed by robots wheeling around to relocate items. These results could be used to make an algorithm that would improve efficiency when it comes to robots not crashing into each other, but quicker. If Amazon wanted to, I hope they’d at least give me some money for it.
