
In this level 2 post, we start the process of a 3-part mathematical modelling series, which will culminate in the answer to one of the most important questions of all time: How should I cross the street?
Introduction
For quite some time now, I have been thinking of a fun problem, and I thought it would be interesting to do a series of posts about it detailing the basics of mathematical modelling. This first post in the series is about the set-up, where we take a real life situation and transform it into mathematics. This process is an essential skill to those pursuing physics and applied mathematics. The best way to learn is by example, so I figured this would be a great way of sharing this fun problem.
The particular problem is one that I have been thinking about off and on for somewhere around 15 years. That’s more than half of my life! It first came to me when I was in elementary school, walking home, and trying to get there quickly. I was on the right street, but the opposite side of the road to my destination. It was a residential street, so I knew cars wouldn’t come very often. I started crossing the street in a sort of diagonal manner, constantly looking down the street in each direction for cars. Of course, if a car came, I would have to make a hard left and get out of the road, and this got me thinking about whether I was taking the best path across the street. The shortest path was the straight line, sure, but the fact that I would have to vacate the road when a car came makes the whole situation a bit different. At the time, I would have had no idea about how to actually find the answer to this question, and it wouldn’t even be until graduate school until I could confidently formulate it. But as a child, my intuition was that the best course would be one that sort of arcs around the straight-line path, at first more directly crossing the street, then to curve down the road more parallel to the curb. I though of it kind of like landing a plane on the opposite curb.
The problem sprung to mind every now and again, whenever I was doing a lot of walking around town, and not too long ago, it came back. I realized that this was a problem that I could model, and potentially solve once and for all. For the past couple of years, I have been noodling around with this problem whenever I didn’t feel like doing anything else (graduate students don’t really have all that much free time). This is the culmination of that work.
The Basic Components
We should start by taking the critical components of this real-life situation and abstracting them into something we can represent with mathematics. Let’s take things one component at a time.
The Street
This is the easiest component to deal with, so it goes first. We only care about the portion of the street between the walker and their destination, and we won’t consider any winding roads. For a first model, we want to keep things relatively simple. The relevant section of the road is just a rectangle, with a width 

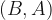

The Walker
What do we need from the walker? Well, they have to have a position (we set them at the origin at the beginning), and they are going to walk along a path that we will pay specific attention to separately. Let’s model the walker as a point, which has a definite position at any given point in time. The fact that a person is an extended object isn’t relevant to the particular problem, so we don’t have to think of them as anything more than a point. In many physics models (especially in intro physics courses), this is often implied, but I want to make things as explicit as possible.
The only other thing we need from the walker is for them to… well, walk. The speed at which the walker travels is going to be important because if the walker is very slow, there is a bigger chance that they will see a car before they reach their destination. To make things as simple as possible, we will assume that the walker walks at a constant speed, which we will call 
The Car
Now we are getting into some real modelling choices. The car is referred to as the car because we don’t care if there are any more after. Once there is one car, the walker is going to get out of the way and that’s that. They are already on the correct side of the street, so there’s no use getting back into the road.
We don’t know when the car will arrive, since cars don’t follow rigorous schedules, they get held up in traffic, sometimes the driver is running a little late or early, etc. The next best thing would be to know about how often cars show up on the road on average. This sounds like we are going to need some probability theory. In particular, we are going to model the car’s arrival as a Poisson process. A Poisson process is one that happens at random, but with an average rate which we can call 


where 
![P([t,t+dt])=\rho(t)\,dt=\Lambda e^{-\Lambda t}\,dt](https://s0.wp.com/latex.php?latex=P%28%5Bt%2Ct%2Bdt%5D%29%3D%5Crho%28t%29%5C%2Cdt%3D%5CLambda+e%5E%7B-%5CLambda+t%7D%5C%2Cdt&bg=ffffff&fg=111111&s=2&c=20201002)
Then, for a larger interval, we just integrate. If it works for buses, this seems to be a reasonable model for our car. Say that the moment the walker begins on their path is the time 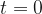

The Path
The path is a little tricky. Really, there are two paths: the intended path and the actual path. The intended path is the path that the walker would take if a car never showed up. The actual path is the path that the walker actually takes, which can be diverted should a car come. Let’s focus first on the intended path.
The intended path can be abstracted in several ways, but let’s start general, and see if we can do anything to make our model (and lives) simpler. The path can be written in a parametric form, 


When we cut off these unnecessary parts of the intended path, we can see that a parameterization is a little too general. Cutting off the horizontal jog in the first diagram ensures that the path can be represented as a function of 


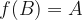
Now we can discuss the actual path. What happens when a car comes? Before, we said that the walker diverts themself off the intended path and onto the other side of the street, but to treat this mathematically, we need to know exactly how this diversion happens. Simplicity is the main driver of our model, so let’s say that the diversion is to immediately finish crossing the street, and then finish walking down the road to the destination, as shown in the figure below.
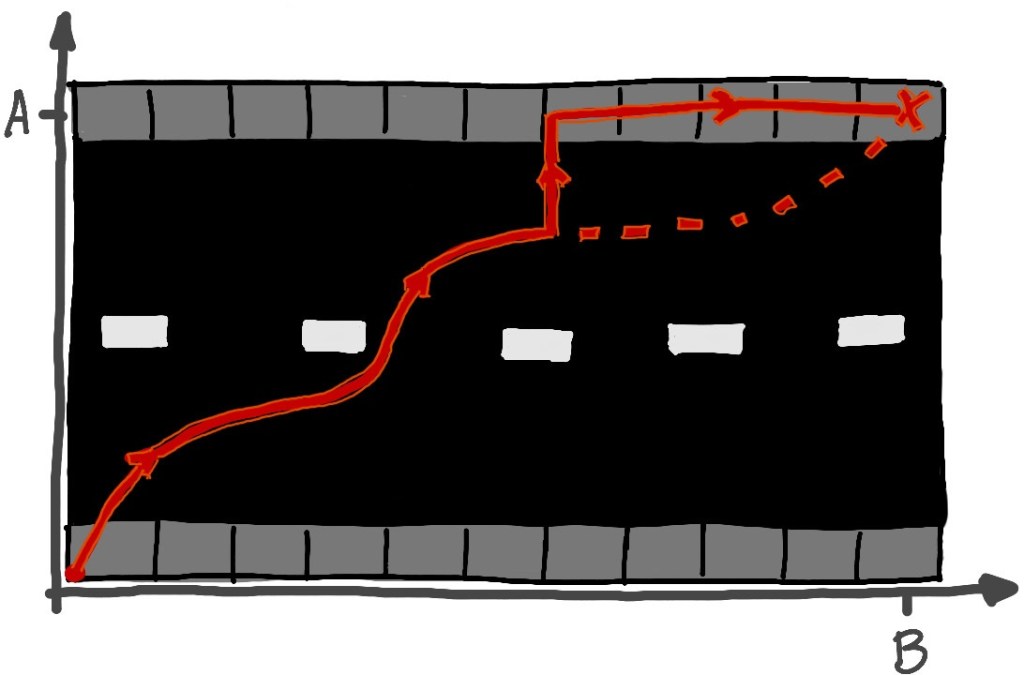
This particular model of the actual path makes calculating distances very easy. The additional distance traveled once the car appears is just 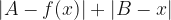
Nondimensionalization
So far, we have a model that consists of several parameters: the lengths of each side of the street, the speed of the walker, and the rate at which cars appear on the road. Four may not seem like many parameters, but in any model, it is best to reduce the number of parameters to as small a set as is possible. One particularly nice way of doing so is called nondimensionalization, and as the name implies, it is about getting rid of the unnecessary “dimensions” of the model. By dimensions, I mean units (like seconds, meters, kilograms, etc.).
We have two relevant units in this problem: length and time. By choosing our particular units of measurement, we can actually cut down on parameters in the model. For example, in high energy physics, we typically choose our units so that the speed of light is equal to 1. Think of the time units as seconds and the length units as light-seconds (the distance light travels in a second). Clearly, in these units, the speed of light is 1 light-second per second. But when we say that the speed of light is 1, we actually mean something even more. The number 1 is unitless, it doesn’t have units of light-seconds per second. This means that in this system, all speeds are just numbers and the units of length and time are the same (like saying a distance of 2 seconds is the distance light travels in 2 seconds). When we are done making predictions, we can reintroduce standard units back into the picture by taking any prediction of lengths (in our weird units where length is in seconds) and multiplying by the speed of light in meters per second, making it a distance in meters. Let’s apply this to our model.
The exact dimensions of the street are not too important to us. We really just care about the overall shape of the rectangle, so we can choose one of the sides to be our unit of distance (making it have length 1). Let’s say that the width of the road is 1, that is 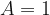
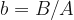
Now let’s get rid of the time units. There are two ways of doing this, by setting 


Our Model
Now that we have all the pieces, we can put everything together into a working model. To do so, we must answer one big question: what does it mean to be the “best path”? There may be several different good answers to this question, but to me, two possibilities stand out. We should either decide that the best path is the one that is the shortest distance (on average) or that the best path should be the path with the shortest travel time (again, on average). Luckily for us, we don’t have to choose between these two options because the walker has a speed of 1, so these turn out to be the same question in this model. To be concrete, we will always think in terms of distances. This will make the problem technically simpler, but I would also encourage the curious to reformulate everything in terms of times to see how this affects the governing equations of the model.
How would we calculate the average distance traveled by the walker? Let’s start by calculating the distance traveled on the actual path, when a car comes. Say that at the moment a car comes, the walker is at the 


Now, in order to calculate the average value, we need the probability associated to each possible distance. We have the probability distribution for a car to arrive at a particular time, but we would like to instead have the probability distribution for a car to arrive when the walker is located at a particular location. The time and

where I have included the

We need to also transform that differential 
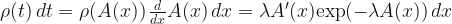
Now, the expected distance traveled by the walker is given by a sum of the possible distances traveled, multiplied by the probability associated with each distance.
![E[f] = \lambda\displaystyle\int_0^b A'(x)e^{-\lambda A(x)}D(x)\,dx + A(b)e^{-\lambda A(b)}](https://s0.wp.com/latex.php?latex=E%5Bf%5D+%3D+%5Clambda%5Cdisplaystyle%5Cint_0%5Eb+A%27%28x%29e%5E%7B-%5Clambda+A%28x%29%7DD%28x%29%5C%2Cdx+%2B+A%28b%29e%5E%7B-%5Clambda+A%28b%29%7D&bg=ffffff&fg=111111&s=2&c=20201002)
I snuck in that last term there without talking about it, so I better fess up. The last term takes into account the possibility that the car does not come before the walker reaches their destination. But you will notice that it is in the form of a distance (the full arclength of the intended path), multiplied by the probability that the car does not come before the walker finishes their journey. This term can be calculated explicitly as an integral (easier when expressing everything in terms of time), so if you are curious how it got there, just do the integral.
Our model is now complete! Our goal from now on will be to find the path that minimizes the expected distance. To see the explicit dependence of the expected distance on the path, I will write everything out in full.
![E[f] = \lambda\displaystyle\int_0^b\sqrt{1+(f'(x))^2}\,e^{-\lambda\int_0^x\sqrt{1+(f'(y))^2}\,dy}\left[\int_0^x\sqrt{1+(f'(z))^2}\,dz + |1-f(x)| + |b-x|\right]\,dx \\ \phantom{\left[\int_0^x\sqrt{1+(f'(z))^2}\,dz + |1-f(x)| + |b-x|\right]}+ e^{-\lambda\int_0^b\sqrt{1+(f'(x))^2}\,dy}\displaystyle\int_0^b\sqrt{1+(f'(x))^2}\,dx](https://s0.wp.com/latex.php?latex=E%5Bf%5D+%3D+%5Clambda%5Cdisplaystyle%5Cint_0%5Eb%5Csqrt%7B1%2B%28f%27%28x%29%29%5E2%7D%5C%2Ce%5E%7B-%5Clambda%5Cint_0%5Ex%5Csqrt%7B1%2B%28f%27%28y%29%29%5E2%7D%5C%2Cdy%7D%5Cleft%5B%5Cint_0%5Ex%5Csqrt%7B1%2B%28f%27%28z%29%29%5E2%7D%5C%2Cdz+%2B+%7C1-f%28x%29%7C+%2B+%7Cb-x%7C%5Cright%5D%5C%2Cdx+%5C%5C+%5Cphantom%7B%5Cleft%5B%5Cint_0%5Ex%5Csqrt%7B1%2B%28f%27%28z%29%29%5E2%7D%5C%2Cdz+%2B+%7C1-f%28x%29%7C+%2B+%7Cb-x%7C%5Cright%5D%7D%2B+e%5E%7B-%5Clambda%5Cint_0%5Eb%5Csqrt%7B1%2B%28f%27%28x%29%29%5E2%7D%5C%2Cdy%7D%5Cdisplaystyle%5Cint_0%5Eb%5Csqrt%7B1%2B%28f%27%28x%29%29%5E2%7D%5C%2Cdx+&bg=ffffff&fg=111111&s=2&c=20201002)
This is a very non-linear problem. We will try some methods at solving this problem in parts 2 and 3 of this series, but for now, let’s gain some intuition for how our model works.
Limiting Behavior
Looking at the limiting behavior of a model is a great way to understand some fundamental features of a model and can also act as checks on calculations to ensure there aren’t mistakes. By “limiting behavior”, I simply mean what we expect to be true of the model in extreme circumstances. In this case, we should look at extreme values of the parameters of our model and gain some intuition about what the best path should look like in these cases.
Let’s start with 
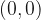


In this case, the expected distance is virtually identical across all paths. If you could imagine the expected distance graphed over function space, it would become very flat around the optimal path in this limit.
A similar thing happens in the limit of large
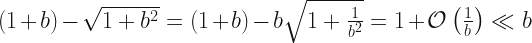
Here, the expected distance is also nearly identical across all paths. This is telling us that if there is any interesting behavior, it will be when
Now, let’s look at 
Finally, the small 
I am expecting to post part 2 in one week, and part 3 the following week. In part 2, we will be looking at ways of tackling this highly non-linear problem analytically. In part 3, we will take a swing at discretizing the problem, so that it may be solved on a computer. I hope that spacing things out in this way will allow those of you who are curious to have some time with this problem before I post my solution(s). You can leave a comment below if you find anything interesting about this problem. See you next week!

2 thoughts on “Crossing the Street – Pt. 1”